[DB] INSDC: Where are the public NGS data stored?
Public databases are filled with a tremendous amount of NGS-based data that can be used for research brainstorming, storyboarding, target selection, and validation. However, finding, identifying, and downloading adequate raw data can be a difficult task. In this post, I will introduce you to the process of effectively using public NGS-based data.
1. Major DBs where NGS data are stored

International Nucleotide Sequence Database Collaboration (INSDC; M Arita et al., NAR, 2021) is a long-standing global collaboration among three primary databases that archive and distribute data from nucleotide sequencing:
-
NCBI’s Genebank BioProject & BioSample (T Barrett et al., NAR, 2011), SRA & GEO
-
ENA: European Nucleotide Archive
-
DDBJ: DNA Data Bank of Japan
These three organizations exchange data on a daily basis to ensure that they all hold the same comprehensive collection of sequence data. They follow the same conventions for data content and format to ensure consistent and high-quality data. The INSDC covers the full spectrum of data raw reads, alignment, assembly, and functional annotation.
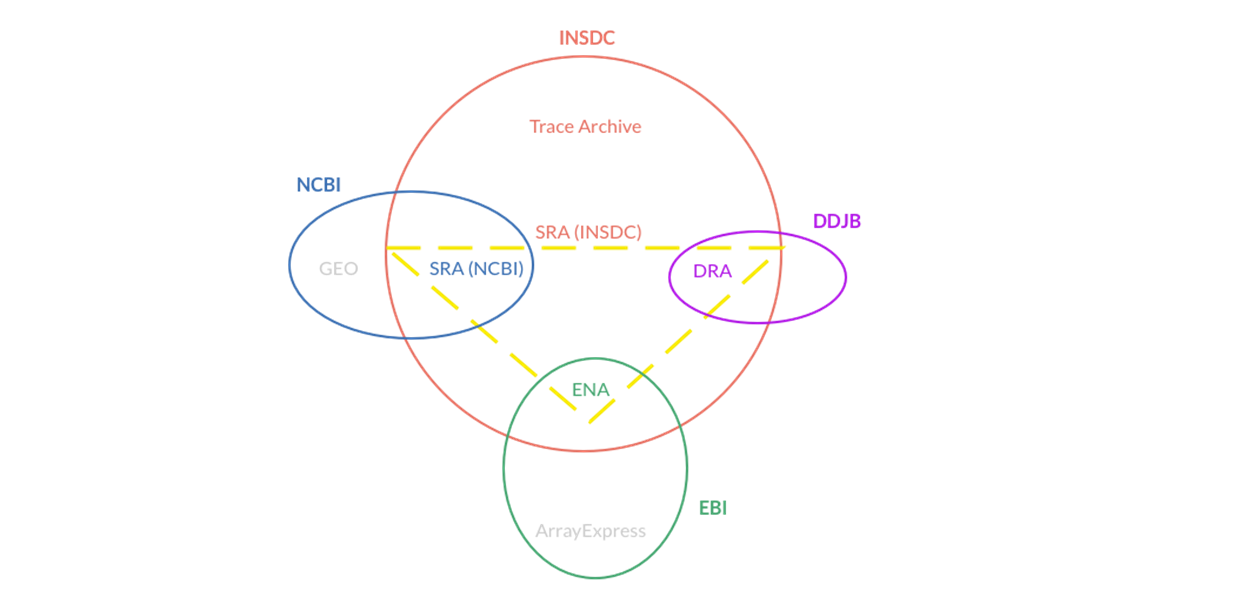
Ref. Gene Expression Repositories Explained
2. Structure of DBs (BioProject, BioSample, SRA & GEO)
To effectively use public data within databases, one must first comprehend the structure of the databases such as BioProject, BioSample, SRA, and GEO, and then choose the appropriate database to collect information tailored to specific needs. These databases are interconnected, with each having the following descriptions:
-
BioProject is a DB for information on the biological project’s scope and purpose and can link to various datasets across different NCBI databases.
-
BioSample contains descriptions of biological source materials (or samples) used in experimental assays.
-
SRA (Sequence Read Archive) stores raw sequencing data and alignment information.
-
GEO (Gene Expression Omnibus) archives processed datasets such as high-throughput gene expression data, functional genomics data sets, and both array-based and sequence-based data..
These DBs indeed share a relationship where data from one can be linked to another. For example, raw data in the SRA may be part of a larger project detailed in BioProject, and samples used for generating such data may be described in BioSample. The processed results from these data could then be stored in GEO.
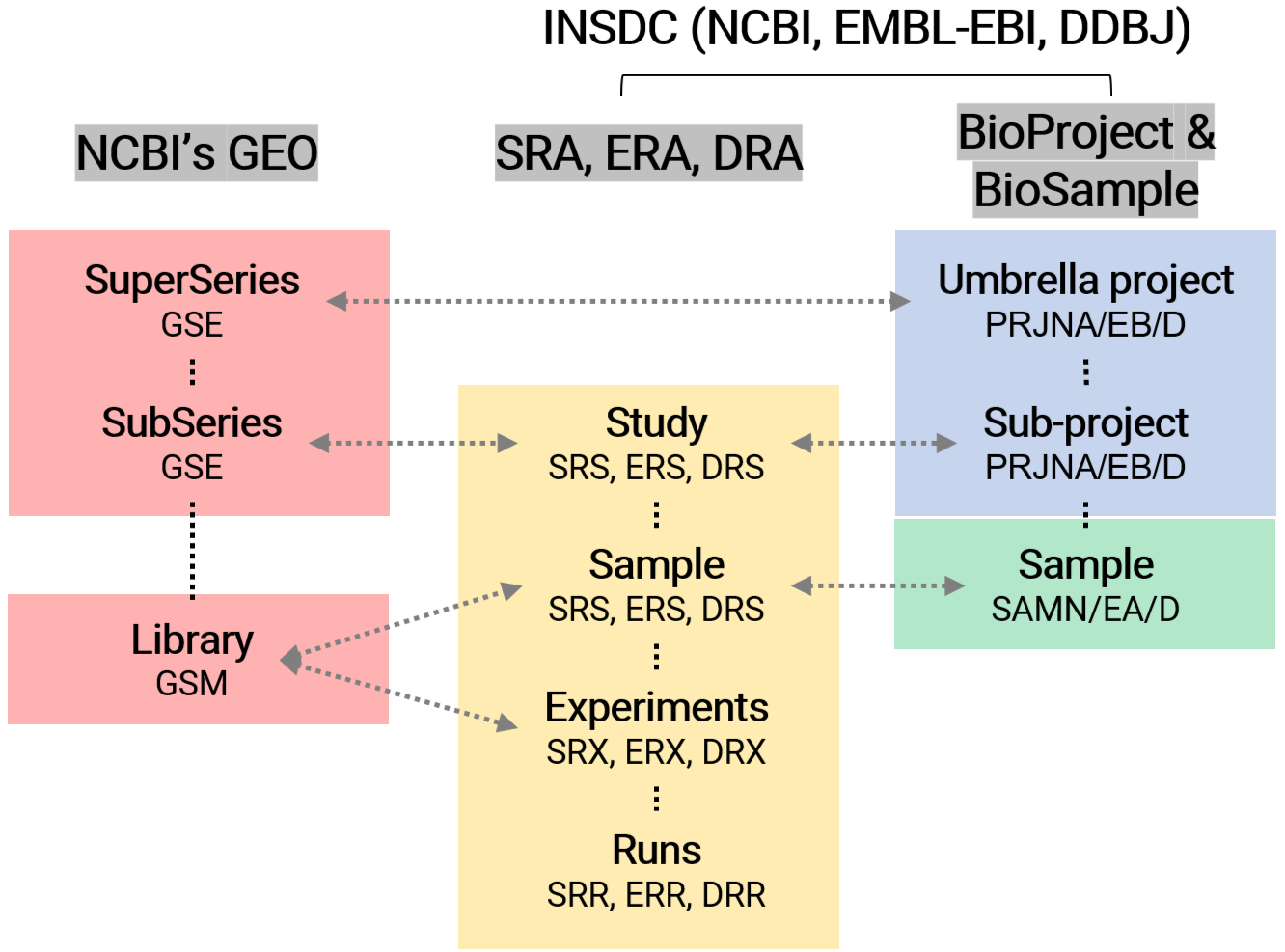
In the process of making my multi-omics data public (Son KH et al., SciAdv, 2023), including RNA-seq, ChIP-seq, and MBD-seq, I prepared and submitted the required metadata spreadsheet to the GEO. A few days later, I was able to verify that IDs for the project and sample data had been issued in the structure illustrated in the image below.
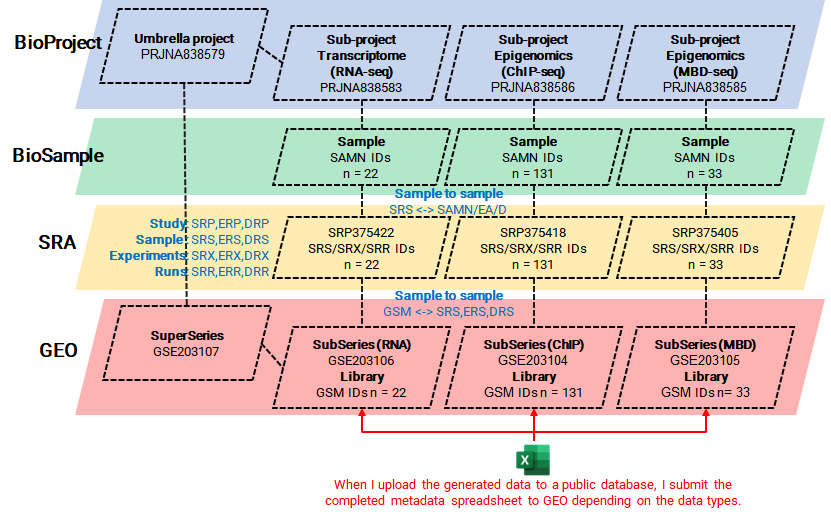
The information verified in each DB was as follows.
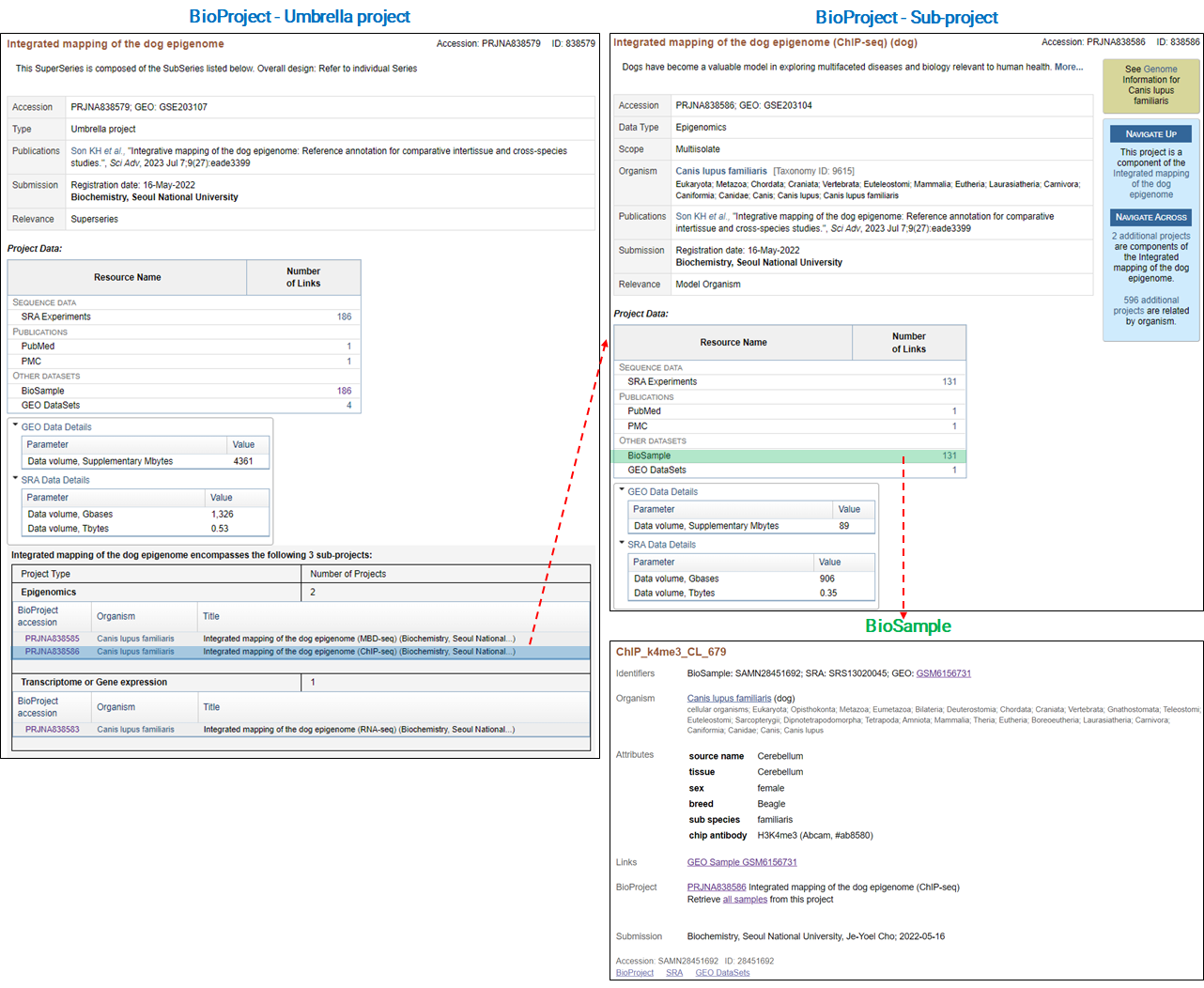
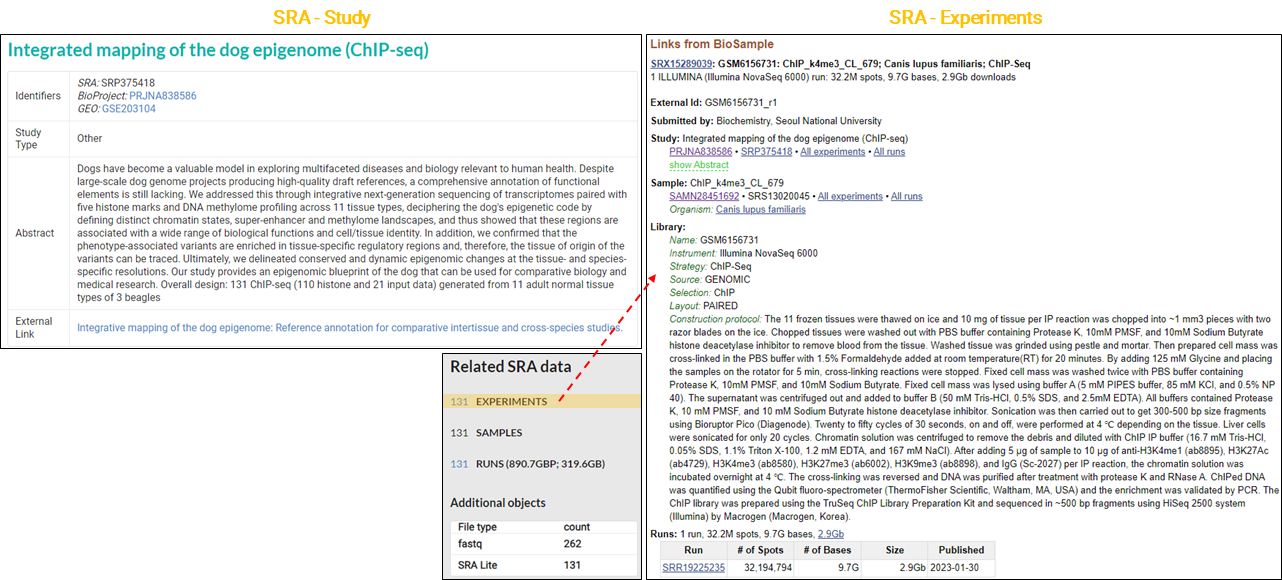
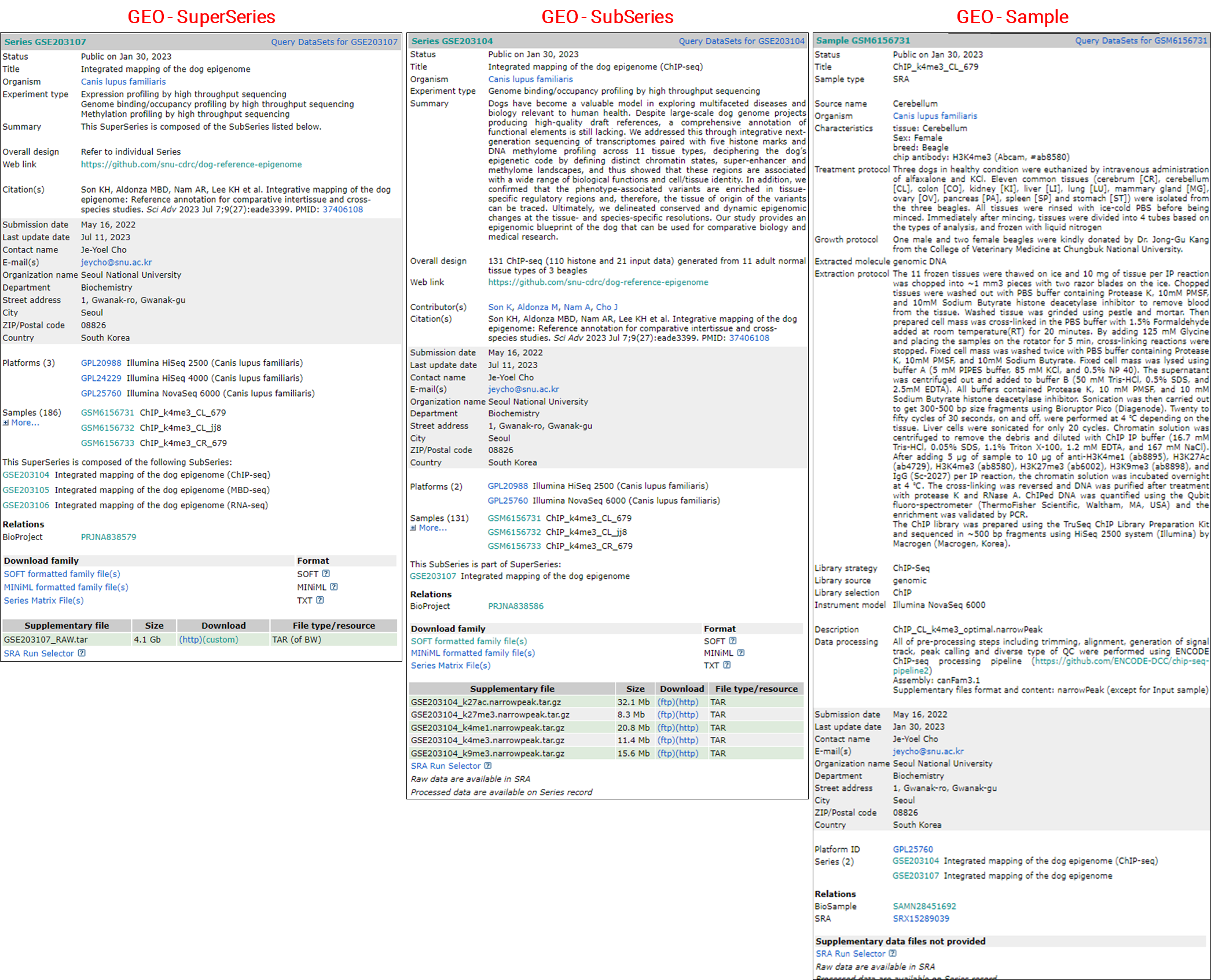
Another example of handling a variety of data types is as follows.
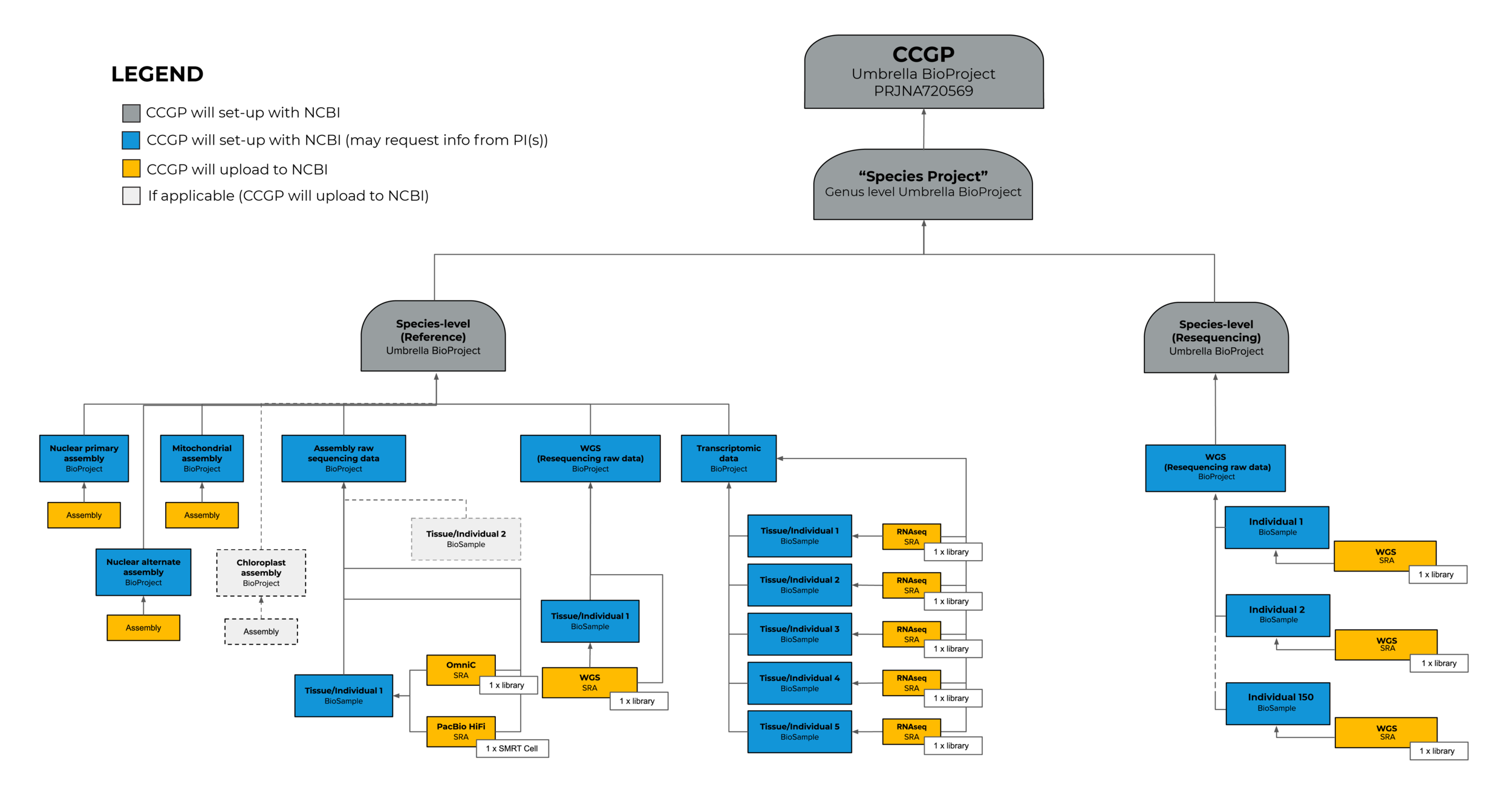
3. Strategies for gathering information of public data
-
Manual Search:
NCBI’s Entrez Global Query Cross-Database Search System
BioProject / BioSample / SRA / GEO -
Programmatic Access:
E-utilities are a set of server-side scripts provided by NCBI for programmatically accessing their databases. These tools allow users to perform automated searches, downloads, and analysis of data from NCBI’s various databases, including GenBank, PubMed, GEO, and SRA. E-utilities are particularly useful for researchers who need to handle large datasets or automate repetitive tasks. They use a standard web protocol (HTTP) for queries, making them accessible from any programming environment that can send HTTP requests.
SRA Toolkit is developed by NCBI specifically for working with data from the Sequence Read Archive (SRA). This toolkit provides utilities for downloading, converting, and analyzing the vast amount of sequencing data stored in SRA. It’s a crucial tool for researchers dealing with high-throughput sequencing data, as it simplifies the process of accessing and manipulating large-scale genomic datasets. The toolkit supports various formats and allows for efficient data management, especially in large-scale genomic projects. -
APIs: Some third-party bioinformatics tools and platforms (ex. BioPython-Entrez)
-
Research Publications
3-1 Manual Search
If you search for several keywords in the NCBI’s Entrez Global Query Cross-Database Search System, you can view the comprehensive number of results.
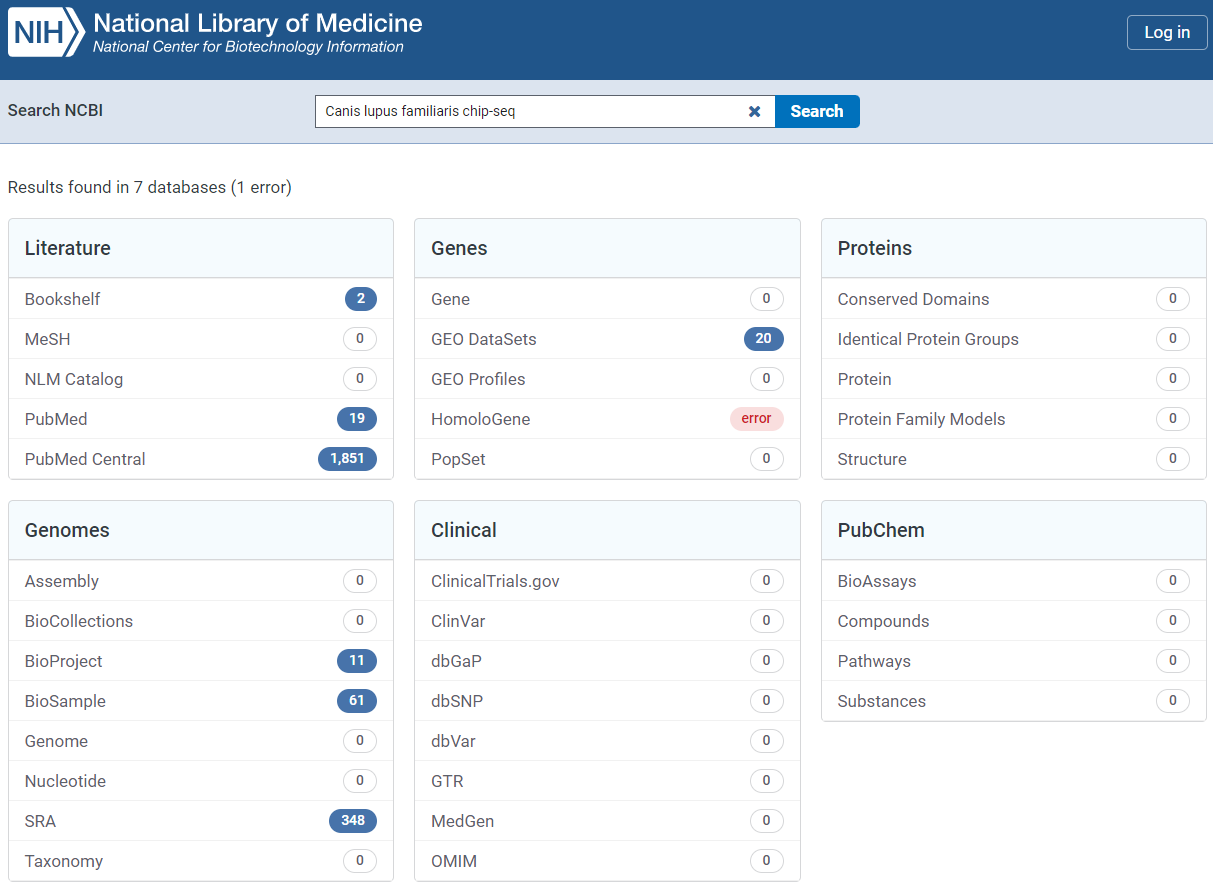
BioProject / BioSample / SRA / GEO
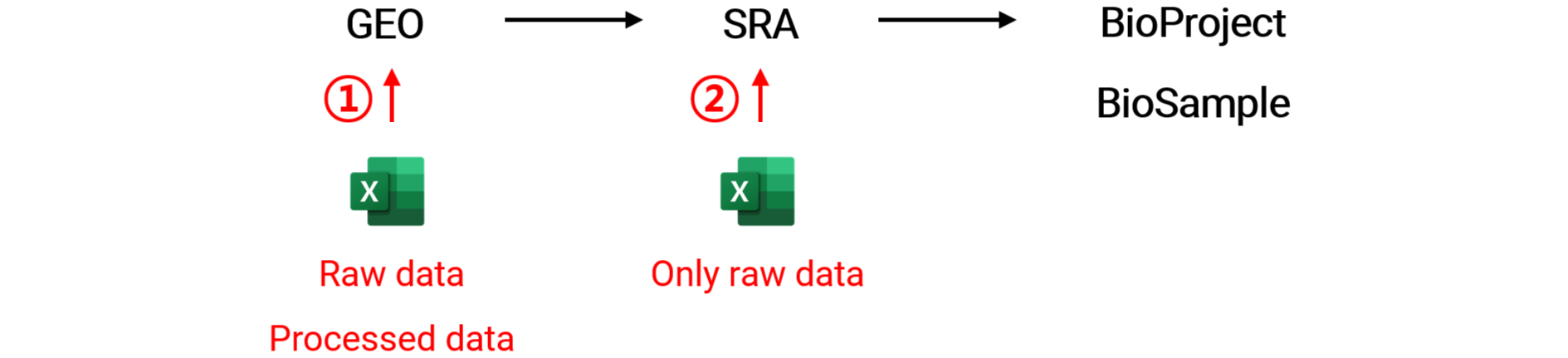
Typically, when we submit NGS-based generated data, there are two options: GEO or SRA. If both raw and processed data are submitted to GEO, IDs for other three DBs are automatically issued. But, If only raw data is submitted to SRA, a GEO ID is not issued. For this reason, SRA and BioProject (BioSample) are initially investigated to collect as much data as possible.
By applying the search rules likes boolean operator (AND, OR, NOT) or fields (ex. Organoism, Source, etc) found in Search in SRA Entrez, you can search for the data you need more efficiently and accurately.
# Example
((canis lupus familiaris[Organism]) AND genomic[Source]) AND ChIP-seq[Strategy]
In the SRA DB, there are 20 fields we can use: Access, Accession, Aligned, Author, BioProject, BioSample, Filter, Layout, Mbases, Modification Date, Organism, Platform, Properties, Publication Date, ReadLength, Selection, Source, Strategy, Text Word, Title.
Indexes that can be used in each field are found in Advanced search; click the “show index list” button. Useful fields are described below.Organism: homo sapiens, mus musculus, canis lupus familiaris, etc.Strategy: wgs, wxs, rna seq, chip seq, ata seq, etc.Source: genomic, transcriptomic, other, etc.Selection: cdna, chip, mnase, cage, other, etc.Layout: paired or single.
3-2. Data gathering with BioPython-Entrez
Link: biopython/Bio.Entrez
Modules
BioPython’s Bio.Entrez module provides an interface to the NCBI’s Entrez service, which allows you to search, retrieve, and download data from NCBI’s databases. The major functions of Bio.Entrez are:
-
Entrez.info()is your window into the vast world of biological data stored in NCBI’s Entrez databases. With this function, you can quickly access essential details about each database, such as its description and available fields. It’s like peeking into a library catalog to see what books are available before diving into your research. This information helps you tailor your queries and streamline your data retrieval process, ensuring you get the most relevant and useful results for your studies. So, next time you’re gearing up to explore the wealth of biological knowledge, don’t forget to start with Entrez.info(). It’s your trusty guide in navigating the NCBI’s treasure trove of data! -
Entrez.read()is used to parse an XML file returned by any of the other Entrez functions. It’s typically used to parse the output ofesearch()andesummary(). -
Entrez.esearch()is used to search an NCBI database. You provide it with a database to search and a search term, and it returns a list of IDs of records that match the search. -
Entrez.efetch()is used to download full records from a list of IDs. You provide it with a database and the IDs of the records you want to download, and it returns those records in a format that you specify.
Entrez.info() & .read()
Here’s a full list of databases you can use in NCBI with the ‘db’ parameter in
# First, import necessary libraries.
from Bio import Entrez
import xmltodict
import json
# Next, always tell NCBI who you are by providing an email address.
Entrez.email = "your.email@example.com" # Always tell NCBI who you are
# We can confirm all of the databases that can be searched.
handle = Entrez.einfo()
record = Entrez.read(handle)
print('# "db" parameter')
print(record["DbList"])

Entrez.esearch()
Here, query is a string of keywords you’re interested in. It might look like “homo sapiens[Organism] AND RNA-Seq[Strategy]”. For the db parameter, use “bioproject” for BioProject, “gds” for GEO, and “sra” for SRA.
# Then, use Entrez.esearch() function to search a database of interest.
# For instance, if you are interested in SRA, you would do:
def search(query):
handle = Entrez.esearch(db="sra", # Database to search
term=query, # Search term
retmax=3 # Number of results to return
)
record = Entrez.read(handle)
return record
# Next, to call this function:
results = search("your_keywords_here")
# The IDs returned by this search are in `results['IdList']`.
print(results['IdList'])
Entrez.fetch()
# Then, use Entrez.fetch() function to fetch the metadata of searched IDs.
def fetch(ls_id):
df = pd.DataFrame()
for id in ls_id:
handle = Entrez.efetch(db="sra",
id=id,
rettype="gb",
retmode="text"
)
# convert xml to dataframe format
xml_data = handle.read()
dict_data = xmltodict.parse(xml_data)
json_data = json.dumps(dict_data)
df_tmp = pd.json_normalize(json.loads(json_data))
# remove complex words in column names
df_tmp.columns = df_tmp.columns.str.replace('EXPERIMENT_PACKAGE_SET.EXPERIMENT_PACKAGE.', '')
df_tmp.index = [id]
# merge dataframes
df = pd.concat([df, df_tmp], axis=0)
return df
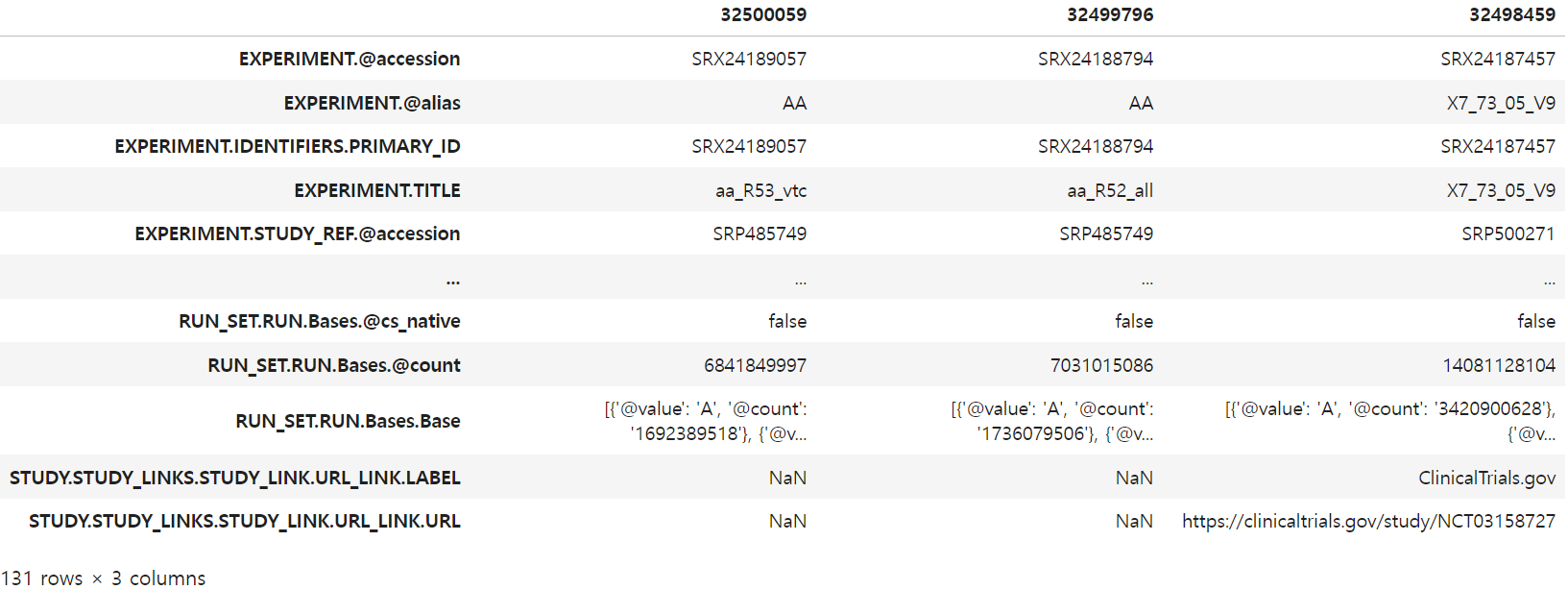
# After calling the function, we can confirm the table of metadata
df_out = fetch(results['IdList'])
df_out.T
Using this functions, I wrote a personalized code for searching and fetching the metadata from SRA database. You can find it on my GitHub repository at keun-hong/sra-meta-fetch.
Other tools for fetching metadata
If you have accession numbers for the public data you need, you can easily gather metadata using various software tools as listed below.
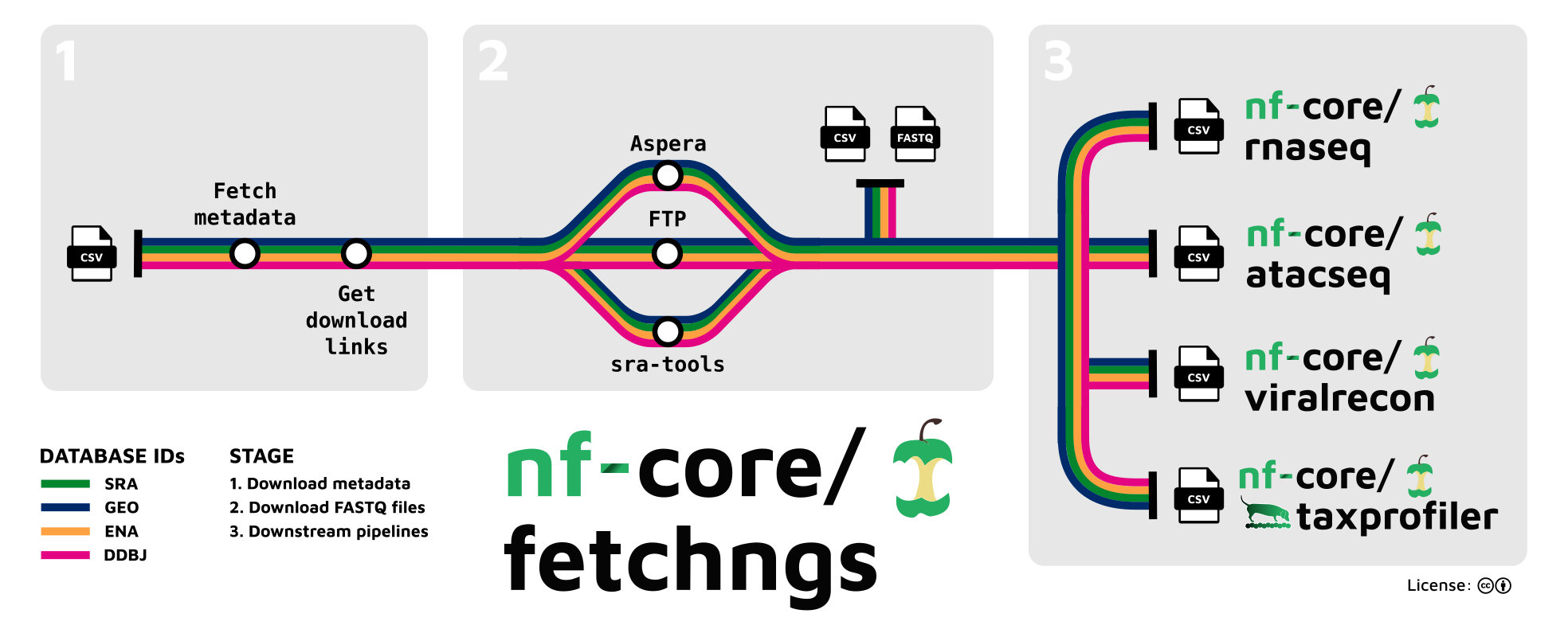
nf-core/ngsfetch
nf-core/fetchngs
GitHub - nf-core/fetchngs
ffq
2301_Bioinfo) Metadata retrieval from sequence databases with ffq GitHub - pachterlab/ffq
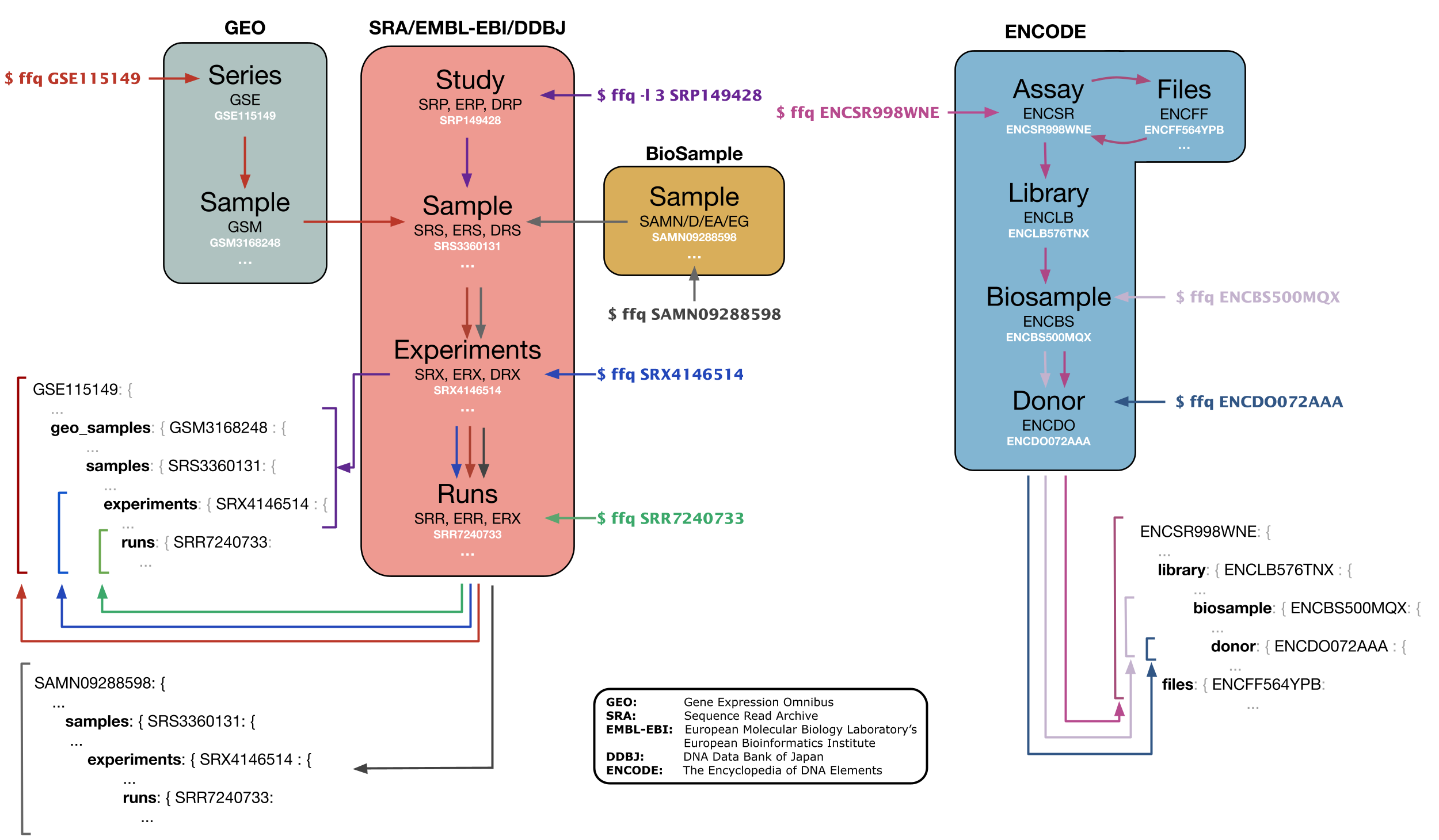
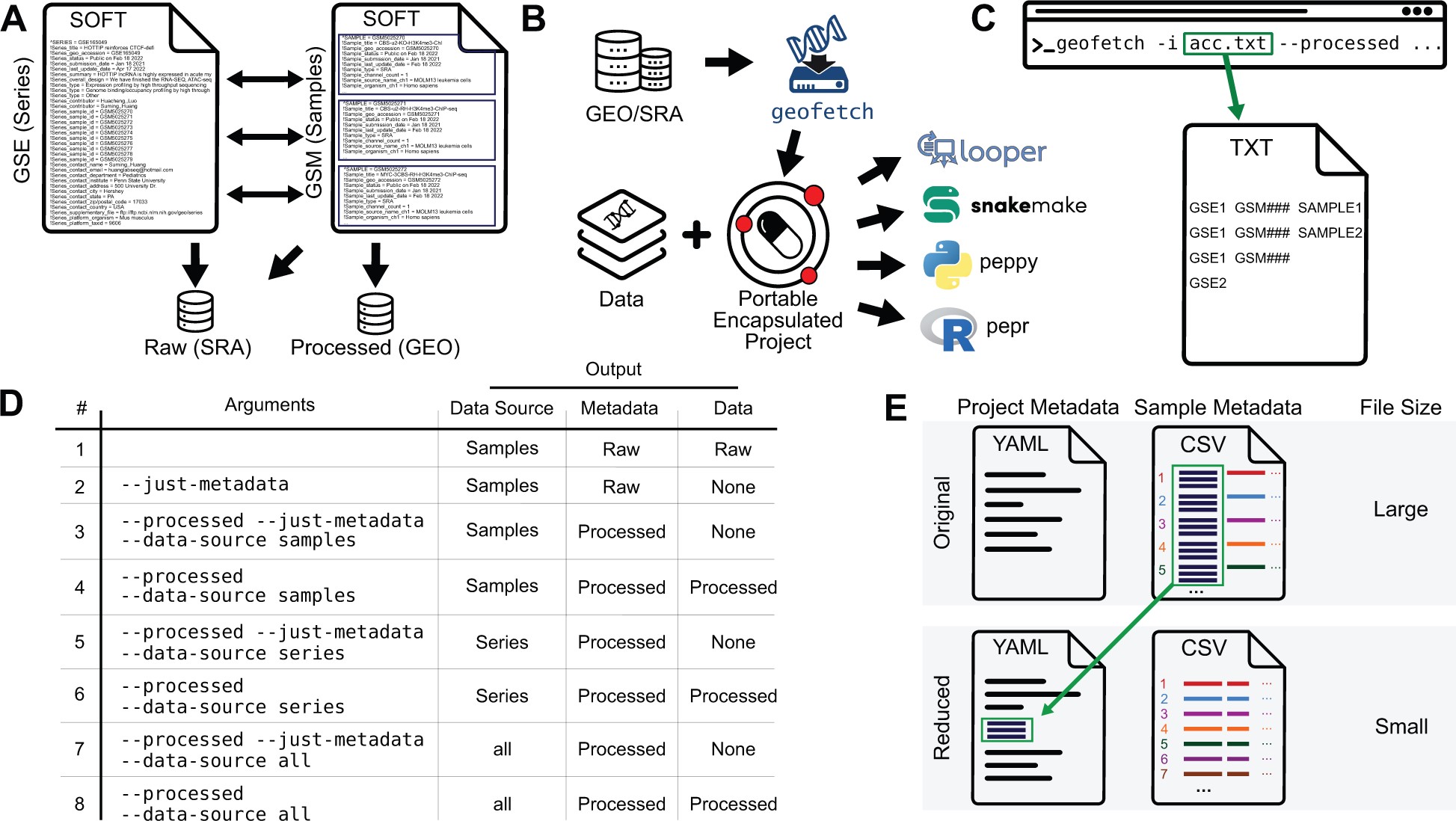
GEOfetch
2303_Bioinfo) GEOfetch: a command-line tool for downloading data and standardized metadata from GEO and SRA
GEOfetch - PEPkit: the bio data management toolkit
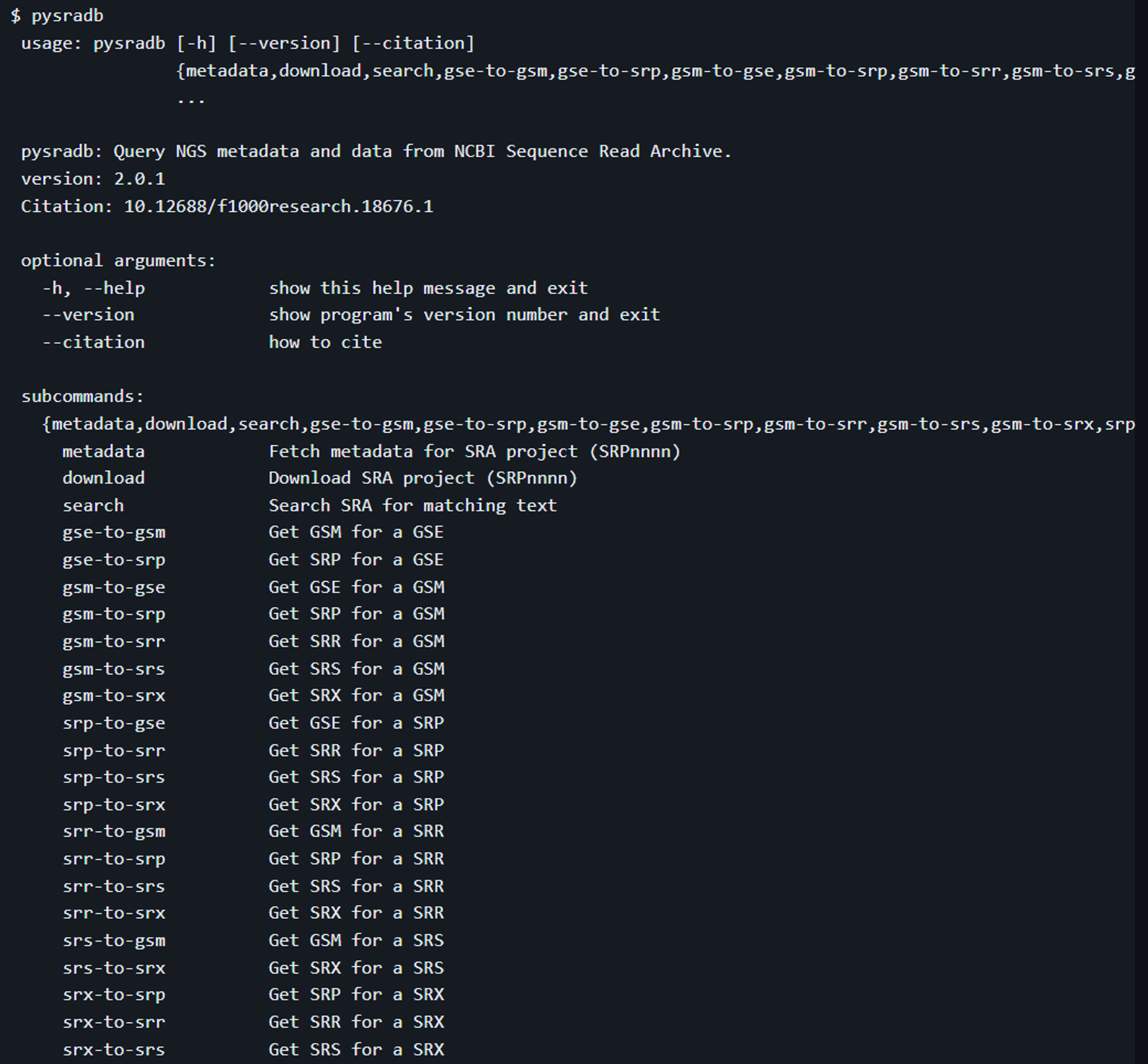
pysradb
1904_F1000) pysradb: A Python package to query next-generation sequencing metadata and data from NCBI Sequence Read Archive
GitHub - saketkc/pysradb
Reference
biopython/Bio.Entrez
incodom.kr/E-utility
Biopython/Bio.Entrez

Leave a comment